

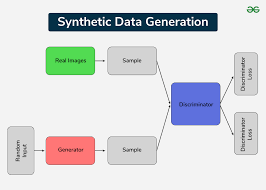
The Synthetic Data Generation Market Size is gaining remarkable momentum as businesses across industries adopt artificial intelligence (AI) and machine learning (ML) at an accelerated pace. Synthetic data refers to artificially generated data that replicates the statistical properties of real-world data without containing actual personal or sensitive information. This technology is increasingly being embraced to overcome challenges related to data privacy, limited data availability, and high costs associated with data collection and labeling. Organizations are recognizing synthetic data as a scalable and secure alternative that empowers innovation while complying with strict data protection regulations.
One of the key drivers of the synthetic data generation market is the rising demand for high-quality training datasets for AI and ML models. Traditional data acquisition processes are often time-consuming, expensive, and constrained by legal restrictions. Synthetic data addresses these concerns by enabling organizations to generate diverse, balanced, and customized datasets at scale. This has proven highly beneficial in industries like finance, healthcare, retail, and autonomous vehicles, where large amounts of reliable data are essential for predictive modeling and decision-making. By offering flexibility and control over dataset characteristics, synthetic data enhances the performance and accuracy of algorithms.
The market is also being fueled by the growing concerns over data privacy and compliance with global regulations such as GDPR and CCPA. Businesses handling sensitive information face significant risks in using real-world data, making synthetic data an attractive solution for reducing privacy breaches. As synthetic data does not link back to real individuals, it provides a safe and compliant method to share data for analytics, testing, and product development. This privacy-preserving quality is accelerating adoption in healthcare for clinical research and in banking for fraud detection systems, where confidentiality is paramount.
Technological advancements are further shaping the market landscape, with startups and established players introducing advanced platforms for automated data generation. Leveraging deep learning, generative adversarial networks (GANs), and advanced simulation techniques, companies are delivering synthetic datasets that closely mimic real-world complexities. These innovations are supporting more accurate testing, faster development cycles, and reduced costs for enterprises. Moreover, the integration of synthetic data solutions with cloud-based platforms is making the technology accessible to businesses of all sizes, boosting its global adoption.
From a regional perspective, North America currently leads the market due to strong investment in AI, advanced digital infrastructure, and significant research and development initiatives. Europe follows closely, driven by strict data protection laws that encourage companies to adopt synthetic data solutions for compliance. Meanwhile, Asia-Pacific is witnessing rapid growth, supported by expanding digital transformation initiatives, government-backed AI programs, and the rising adoption of autonomous technologies in countries such as China, Japan, and India. These dynamics highlight a promising global outlook for synthetic data solutions across industries.
Looking ahead, the Synthetic Data Generation Market is expected to expand rapidly as enterprises recognize its potential to unlock innovation, mitigate privacy concerns, and accelerate digital transformation. With applications ranging from autonomous vehicle testing and fraud detection to healthcare research and retail personalization, synthetic data is poised to become a foundational enabler of AI-driven systems. The future will likely see greater standardization, interoperability, and broader industry collaborations, further solidifying the role of synthetic data as a transformative force in the modern data ecosystem.